Hacking YouTube With MP4
I accidentally discovered a potential vulnerability in YouTube during a late night debugging session on a MP4 muxer. This is a story how a simple bug in my own code made me rethink the security implications of a video transcoding pipeline.
Understanding Muxers
If you don’t know what a “muxer” is, that’s fine. I didn’t have a single clue either, up until I had to actually fix one.
Muxing is an abbreviation of multiplexing. Muxing is the process of encapsulating multiple encoded streams – audio, video, and subtitles (if any) – into a container format, such as AVI, Ogg, or Matroska. (Quoted from VideoLAN)
A muxer is just a term used to describe piece of software that performs multiplexing.
My muxer had a bug, a serious one. I had set it to record 10 seconds of video footage yet it outputted a sped up version of 8 seconds. The muxer being open source and written in Golang, made me think that this should be a relatively easy issue to fix. Just modify some timestamps, right?
Well, turns out there are quite a few types of timestamps in the MP4 format:
- Decode Timestamps (DTS): when to decode the frames
- Presentation Timestamps (PTS): when to present the frames on the screen
- Composition Timestamps (CTS): when to compose a frame
Each of them serve a distinct purpose but my bug resided in the presentation timestamps, my video frames were not being displayed on time correctly.
Timestamps in the MP4 format are not your typical format (unix timestamps, …). Instead they are actually more of a duration difference between the start and the end of a video.
Let’s assume you want to display a frame at the fifth second mark, you would transform it as follows:
ts = 5 * timeScale
Where the timeScale is an arbitrary value that you can pick, essentially saying to the decoders that:
1 second = timeScale
Discovering The Bug
One of the bugs in my muxer was that I announced to use a timeScale of ‘12,000’ in my MP4 header but in reality it was using a timeScale of ‘10,000’ when calculating durations. This led to an interesting side effect, the decoder essentially thought that a presentation timestamp of 20,000 was 1.6 seconds instead of 2 seconds.
I was playing with the presentation timestamp values and suddenly produced this video of 4MB yet claimed to have 15 hours of footage.
Now, what would you do if you come across such a strange file? Well, I uploaded it to YouTube and to me suprise it didn’t get rejected for being longer than 12 hours. In fact, the thumbnail service was attempting to generate thumbnails for the video. A few days went by and it finally resulted in an error message
Processing abandoned Video is too long.
Assessing The Impact
I decided to do some tests and generated video files and see how they behave throughout the video pipeline. So I made a three hour video version which was 4MB as well, but after it had been processed by YouTube it had become a monster of 825MB.
This gave a clue as to what is happening behind the scenes, YouTube always transcodes videos to a variety of formats (4k, 1080p, 720p, etc..) But in the processes also ensured Constant Frame Rate (CFR), which is a fancy word for saying that every second of video footage contains exactly the same amount of frames. The alternative is Variable Frame Rate (VFR) which can be interesting if you’re optimizing for storage.
Given that the video of 3 hours had been inflated by 20,600% due to this configuration, I had decided to ramp this up. I had settled on a video that had the length of 750 days, and by my calculations, it should have resulted in a video file of several terabytes.
Reporting To YouTube
As a result of this I decided to report it to YouTube as a potential security issue and not too long after that I received an email:
Hello,
Thanks for reporting this bug. We have notified the team about this issue; they will review your report and decide whether they want to make a change or not.
As a part of our Vulnerability Reward Program, we decided that it does not meet the bar for a financial reward, but we would like to acknowledge your contribution to Google security in our Hall of Fame:
https://bughunter.withgoogle.com/rank/hm
If you wish to be added to the Honorable Mentions page, please create a profile here: https://bughunter.withgoogle.com/new_profile
Your ranking is based on the number of valid reports.
Regards, Google Security Bot
To the best of my knowledge, the impact was rather low because their transcoders are setten up in such a way that they will eventually give up on file if it takes too many resources.They didn’t disclose what exactly was happening behind the scenes so I can only guess. I believe that it was the service responsible for generating thumbnails that has to decode the file would eventually give up on trying and that caused the video to remain stuck in the “in processing” phase.
Bonus: naive duration estimation is a sin
A MP4 file can lie about the duration in their header and contain a much longer video than it initially claimed.
For example, we can have the metadata box claim a duration of 15 minutes but have a video of 24 hours. The transcoding process will typically recalculate the final duration and doesn’t rely on the metadata.
It’s important that when you’re validating the duration of a video that you are deriving it from the real video frames rather than the metadata.
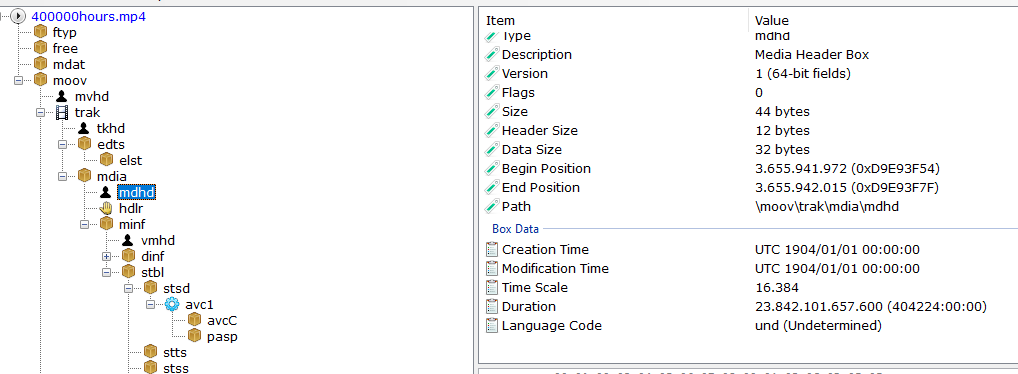
The metatadata is located at:
MOOV -> TRAK (video) -> MDIA -> MDHD
Takeaways?
- The size of a video file is not an proper indicator for how long it is
- CFR transcoding can lead to DoS issues if you fail to validate the duration properly
- Validate the duration of a video properly, don’t rely on the metadata
Hacking YouTube With MP4 https://t.co/OWhWw76Nl6
— KeyboardWarrior (@Keyb0ardWarr10r) October 11, 2021